NORTH¶
TLDR: Add function-preserving neurons whose activations are as “orthogonal” as possible to the current layer.
NORTH [MRLW22], short for Neural Orthogonality, proposes several heuristic growth criteria, centered around the idea is that a layer should grow the activations are “saturated”, in the sense that the current activations span many independent directions.
Notation and framework¶
Consider an MLP with hidden layer \(l\), current width \(C_l\), preactivations \(\boldsymbol{Z}_l\), activations \(\boldsymbol{H}_l\), and fan-in weight matrix \(\boldsymbol{W}_l\). For \(n\) buffered samples, the dense activation matrix is treated as \(\boldsymbol{H}_l \in \mathbb{R}^{n \times C_l}\).
NORTH follows a simple dynamic growth loop:
Perform a gradient descent step on the existing network.
For each hidden layer \(l\), evaluate a trigger \(T(f,l)\).
If \(T(f,l) = k > 0\), add \(k\) neurons to layer \(l\) using the corresponding initialization.
The trigger therefore answers all three growth questions at once: a positive value says when to grow, the layer index says where, and the value \(k\) says how many neurons to add.
1. Activation orthogonality trigger¶
The main NORTH trigger measures the orthogonality of one layer’s activations across a batch:
where \(\epsilon > 0\) is some small threshold. Note that \(0 \le \phi_a^{ED} \le 1\). Because the metric is based on the singular values of the \(n \times C_l\) activation matrix, the paper requires \(n > C_l\). When \(\phi_a^{ED}\) is high, the layer’s activations are mostly orthogonal; when it is low, the layer has redundant or collapsed activation directions.
NORTH compares the current metric to its value at initialization:[1]
where \(f_0\) is the initial network and \(\gamma_a\) is a threshold hyperparameter close to \(1\). Multiplying by \(C_l\) converts the normalized excess orthogonality back into a number of neurons.
The baseline \(\phi_a(f_0,l)\) matters because orthogonality usually deteriorates as activations pass through deeper nonlinear layers. NORTH therefore asks the layer to maintain roughly its initial relative activation diversity as it grows. If adding neurons does not increase the effective rank, the normalized metric falls and the trigger stops firing until training creates new independent directions.
2. Weight orthogonality trigger¶
NORTH-Weight uses the same idea, but measures orthogonality of the fan-in weight matrix rather than the activation matrix:
This is generally cheaper to compute, however weight orthogonality does not guarantee activation orthogonality. NORTH-Weight is also bounded by input dimensionality: once the layer is wider than the dimension of its fan-in space, the weight matrix cannot keep adding new independent singular directions.
3. Gradient trigger as a comparison¶
The paper also introduces a gradient-based trigger to put prior gradient-based initializations. Following GradMax, the maximum contribution to the gradient of \(k\) added neurons \(\frac{\partial L}{\partial \boldsymbol{w}_\textrm{new}^{in}}\) is given by the top-k singular values of \(\left(\frac{\partial L}{\partial \boldsymbol{Z}_{l+1}}\right)^{\top} \boldsymbol{H}_{l-1}\).
The proposed trigger counts singular values of \(\left(\frac{\partial L}{\partial \boldsymbol{Z}_{l+1}}\right)^{\top} \boldsymbol{H}_{l-1}\) that are larger than the total gradient norm of the existing neurons in the layer:
Intuitively, this trigger compares the gradient contribution of new neurons to that of existing neurons.
4. Function-preserving initializations¶
NORTH* methods differ primarily in how they choose the fan-in weights of new neurons. In all cases, the fan-out weights are initialized to zero:
such that they are function-preserving. The initialization strategies considered are:
Strategy |
Trigger |
New fan-in initialization |
|---|---|---|
NORTH-Select |
\(T_{act}\) |
Generate random candidates and select those maximizing activation orthogonality. |
NORTH-Pre |
\(T_{act}\) |
Generate candidates whose preactivations lie in directions orthogonal to the current pre-activations and select those maximizing activation orthogonality. |
NORTH-Random |
\(T_{act}\) |
Use the random fan-in initialization. |
NORTH-Weight |
\(T_{weight}\) |
Project random fan-in weights onto the kernel of \(\boldsymbol{W}_l\). |
NORTH-Select and NORTH-Pre are both approximations to the ideal selection strategy that maximizes activation orthogonality: NORTH-Select samples random candidates, while NORTH-Pre samples candidates whose preactivations are orthogonal to the current preactivations. In both cases, the generated candidates are selected according to activation orthogonality. An optimization approach was tested that directly optimizes the activation orthogonality, but this was found to be too computationally expensive.
5. When, how many, and where to grow?¶
When to grow? The paper evaluates triggers after gradient steps. In principle this gives a highly adaptive schedule; in practice, evaluation frequency is a computational hyperparameter. Evaluating every mini-batch makes the method responsive but expensive, especially for SVD-based activation metrics and candidate selection.
How many? The number of new neurons is the positive trigger value. For activation-based NORTH this is the width-scaled excess of the current orthogonality metric over its threshold:
Practical implementations still impose a maximum width, because poorly tuned thresholds can otherwise lead to excessive growth.
Where to grow? Each hidden layer is evaluated independently. NORTH therefore grows layers whose current activations or weights appear to have enough independent directions, and leaves other layers unchanged.
6. Experiments¶
The CNN experiments use CIFAR-10 and CIFAR-100, average over 5 seeds, and train with Adam, cosine annealing, Xavier initialization, batch size 128, and \(\epsilon = 0.01\) for the effective-dimension metric \(\phi^{ED}\). For VGG-11 on CIFAR-10, activation-trigger experiments sweep \(\gamma_a \in \{0.9, 0.97, 0.99\}\); the other CIFAR activation-trigger experiments use \(\gamma_a = 0.9\). Weight-trigger experiments use \(\gamma_w = 0.99\).
For convolutional activation triggers, the paper replaces the initialization baseline \(\phi_a(f_0,l)\) with the running maximum \(\max_t \phi_a(f_t,l)\), because late-layer CNN orthogonality metrics can be close to zero at initialization.
Setting |
VGG-11 |
WRN-28 |
|---|---|---|
Learning rate |
\(3\cdot10^{-4}\) |
\(3\cdot10^{-3}\) |
Epochs |
100 |
50 |
Initial width |
\(0.25\times\) |
\(0.25\times\) |
Medium static width |
\(1\times\) |
\(1\times\) |
Maximum width |
\(2\times\) |
\(6\times\) |
For WideResNet-28, residual blocks couple channel dimensions, so NORTH grows whole groups based on the first layer’s metric and disables residual connections while evaluating activation- and weight-based metrics. WideResNet uses batch normalization; the CIFAR experiments otherwise do not use data augmentation or dropout.
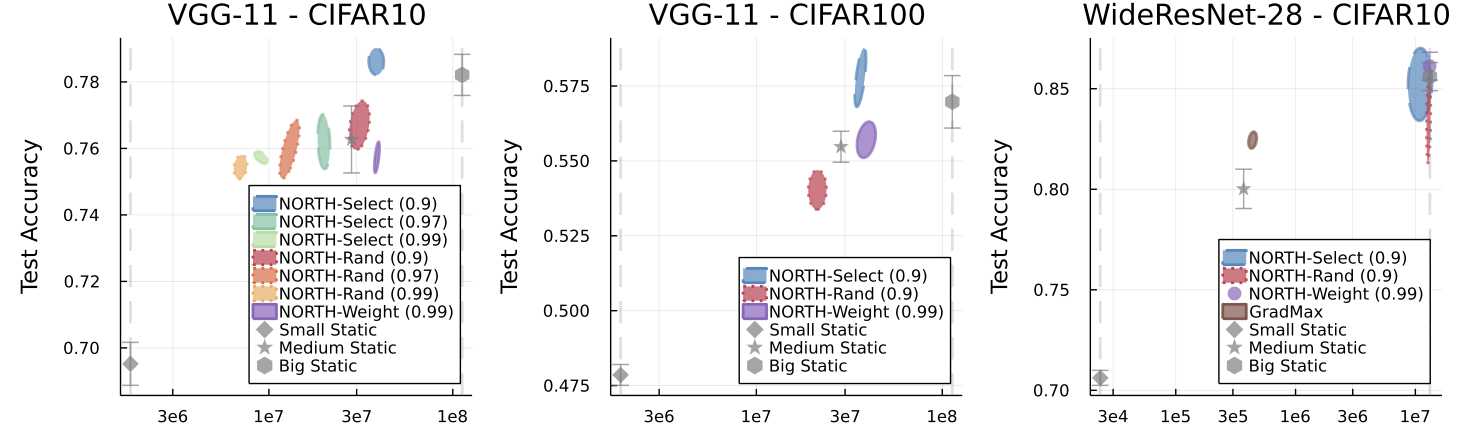
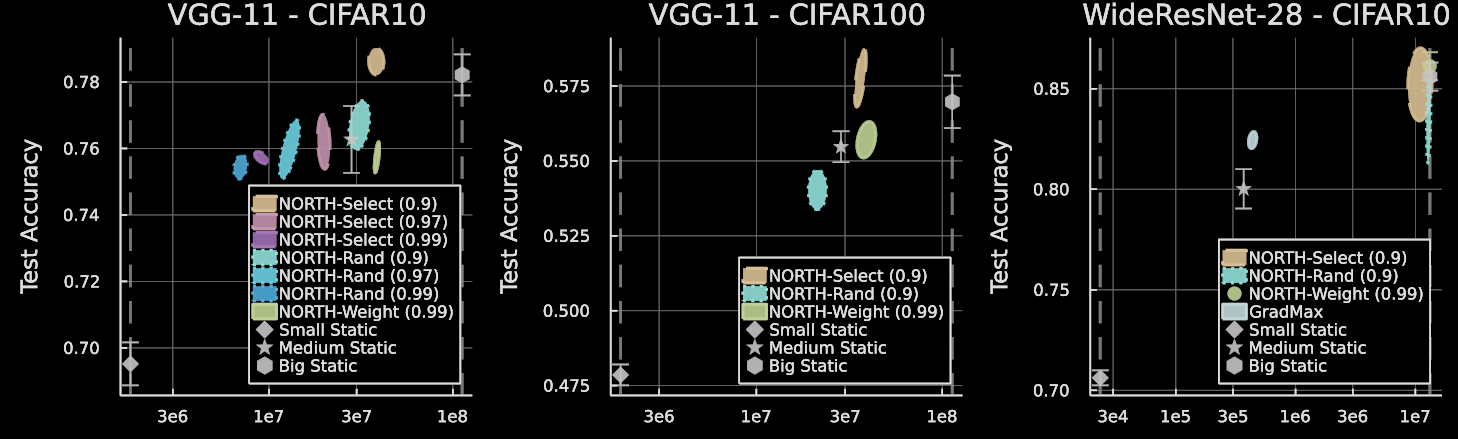
NORTH* results on CIFAR-10/100.
For MLPs on MNIST, the dynamic NORTH* methods sit on the Pareto front of test accuracy versus network size. NORTH-Select, NORTH-Weight and NORTH-Random reach competitive accuracy, while NORTH-Pre does not grow sufficiently large (but still sits on the pareto front).
For VGG-11 on CIFAR-10 and CIFAR-100, NORTH-Select can outperform larger static baselines with fewer parameters. For WideResNet-28, NORTH* methods often grow to or near the maximum allowed size. The paper attributes this partly to the constraints introduced by residual connections.
Are we really maximizing activation orthogonality?¶
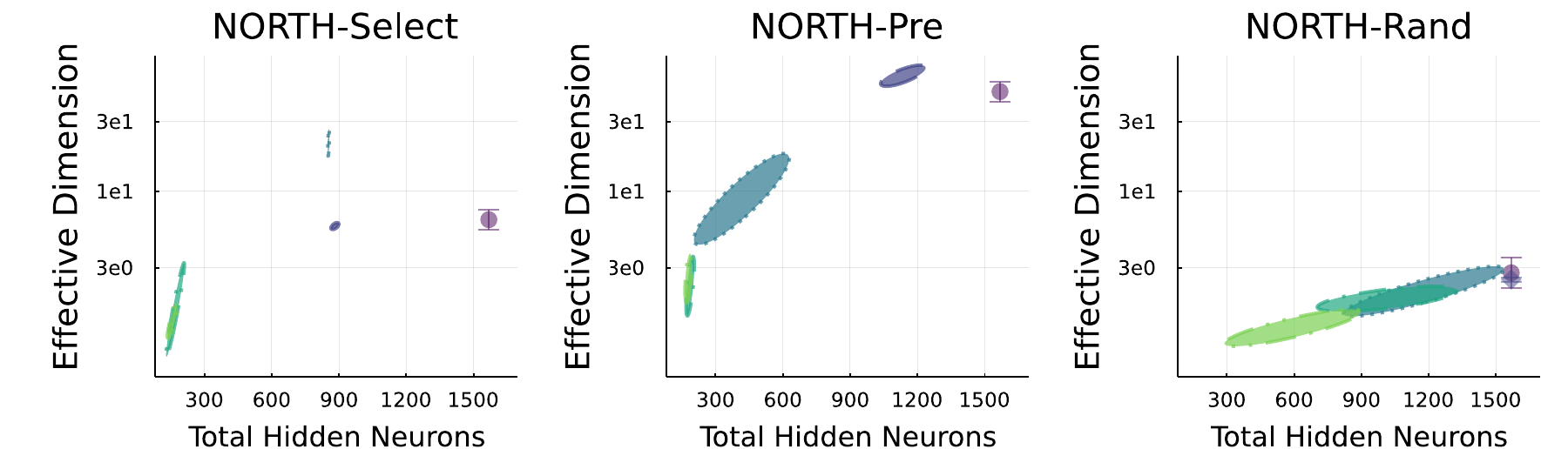
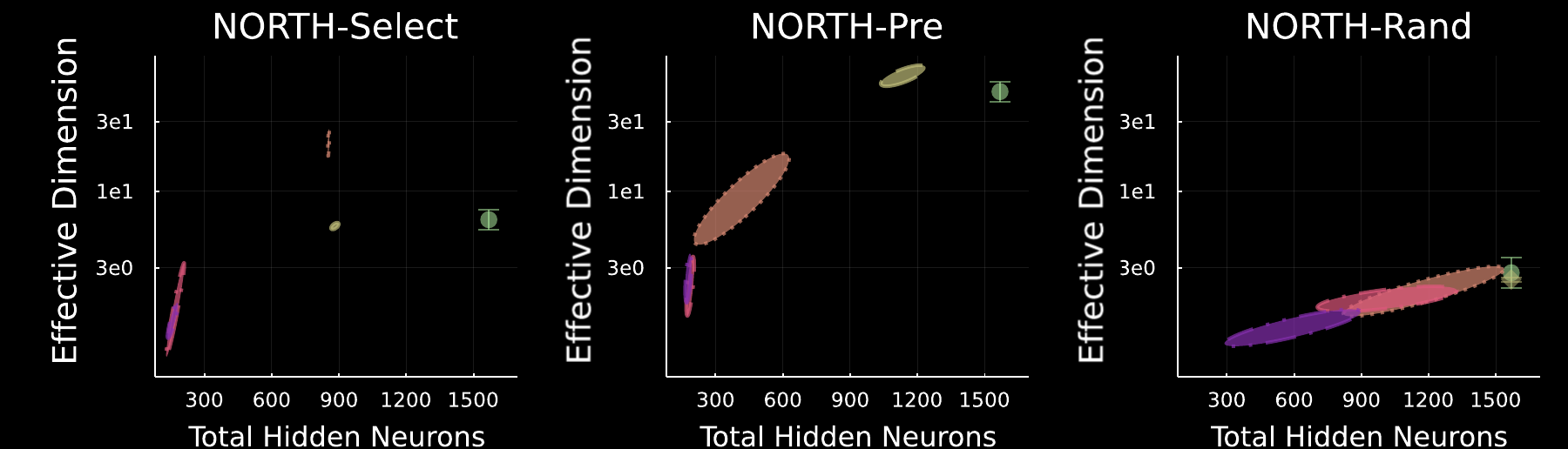
Effective dimension \(\phi_a^{ED}\) vs parameter count for MLPs on MNIST.
The fact that NORTH-Select outperforms NORTH-Pre is surprising, since NORTH-Pre generates candidates which already maximise pre-activation orthogonality and therefore should maximise activation orthogonality better than random candidates.
Indeed, in MLP experiments on MNIST, NORTH-Pre (middle panel) appears to maximise activation-orthogonality \(\phi_a^{ED}\) (a.k.a. Effective Dimension) more aggressively than NORTH-Select (left panel), but performs worse, at least on the larger convolutional networks. This suggests that activation orthogonality, as measured by \(\phi_a^{ED}\), is a useful heuristic but not the optimal criterion to optimize directly.
Footnotes¶
References¶
Kaitlin Maile, Emmanuel Rachelson, Hervé Luga, and Dennis George Wilson. When, where, and how to add new neurons to ANNs. In Proceedings of the First International Conference on Automated Machine Learning, 18/1–12. PMLR, 2022. ISSN: 2640-3498. URL: https://proceedings.mlr.press/v188/maile22a.html.